Research & discovery
Three rounds before a single screen was designed
I ran research across three cohorts, starting with high-engagement outliers to understand what completing CQs actually looked like when it worked, then moving to concept testing and usability validation.
Round 0 — Behavioral outlier interviews
I started with the clients who were completing 50+ assessments, far above average
I wanted to understand what made them different, because their behavior was what we were trying to cultivate. Three things consistently came up: their therapist had set the expectation that CQs were part of therapy; they used them for self-reflection between sessions; and therapist follow-up mattered to them. CQ completion wasn't a platform habit. It was a relational one.
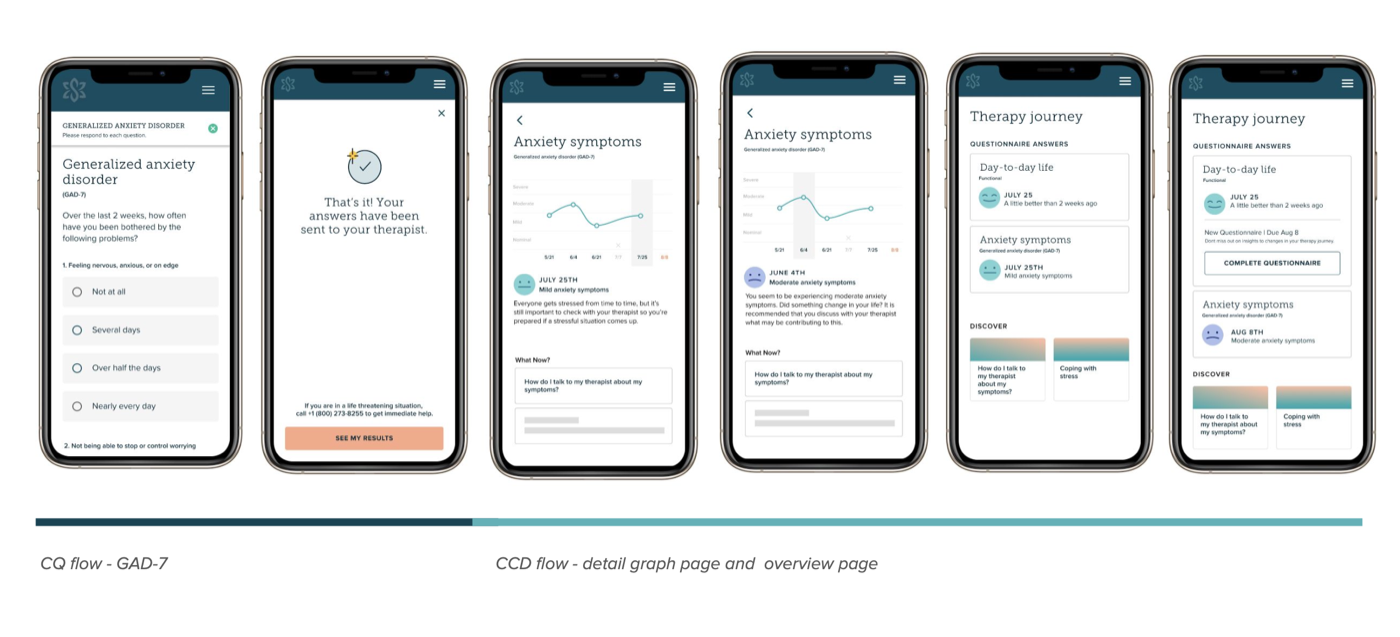
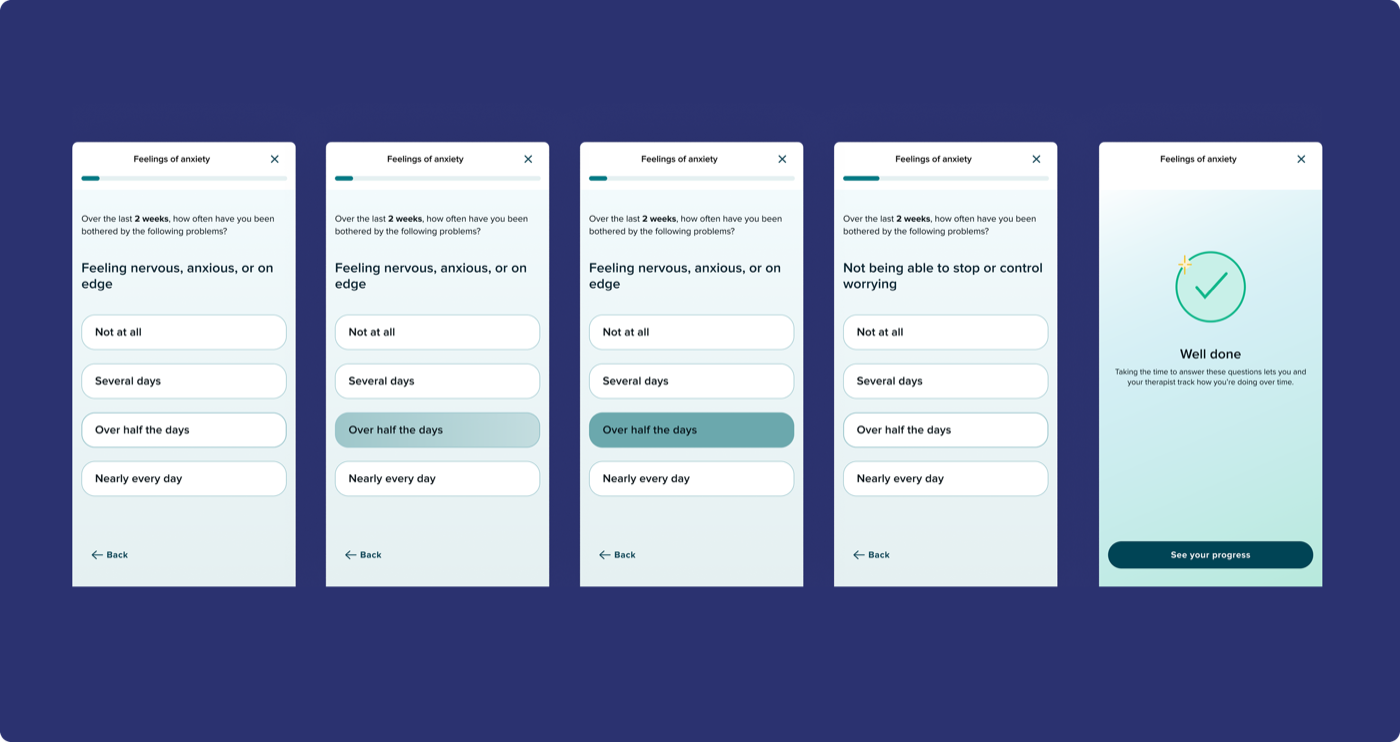
Round 1 — Unmoderated concept testing · 6 participants
100% expected a graph. None of them wanted to feel judged by an app.
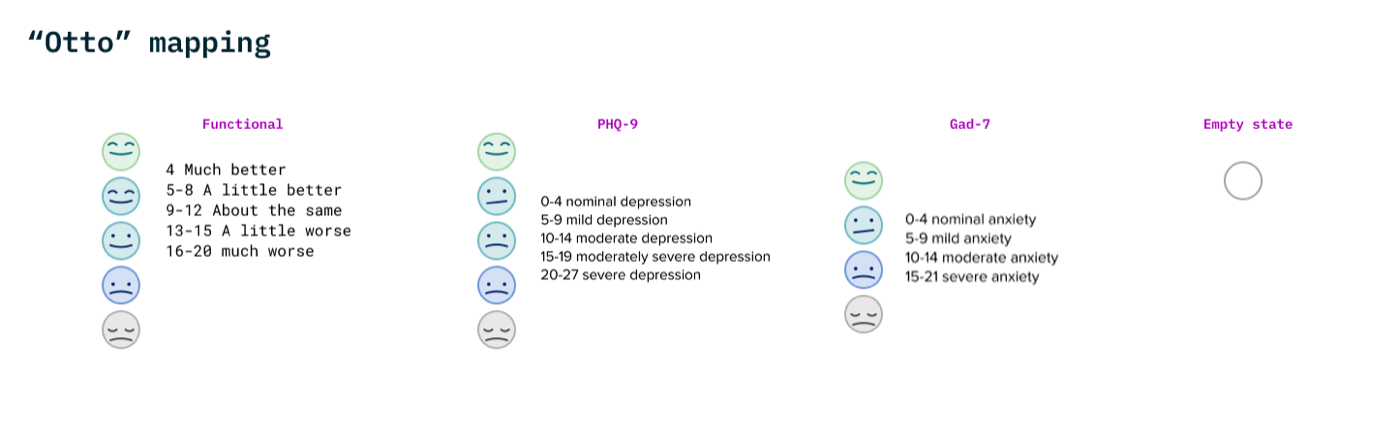
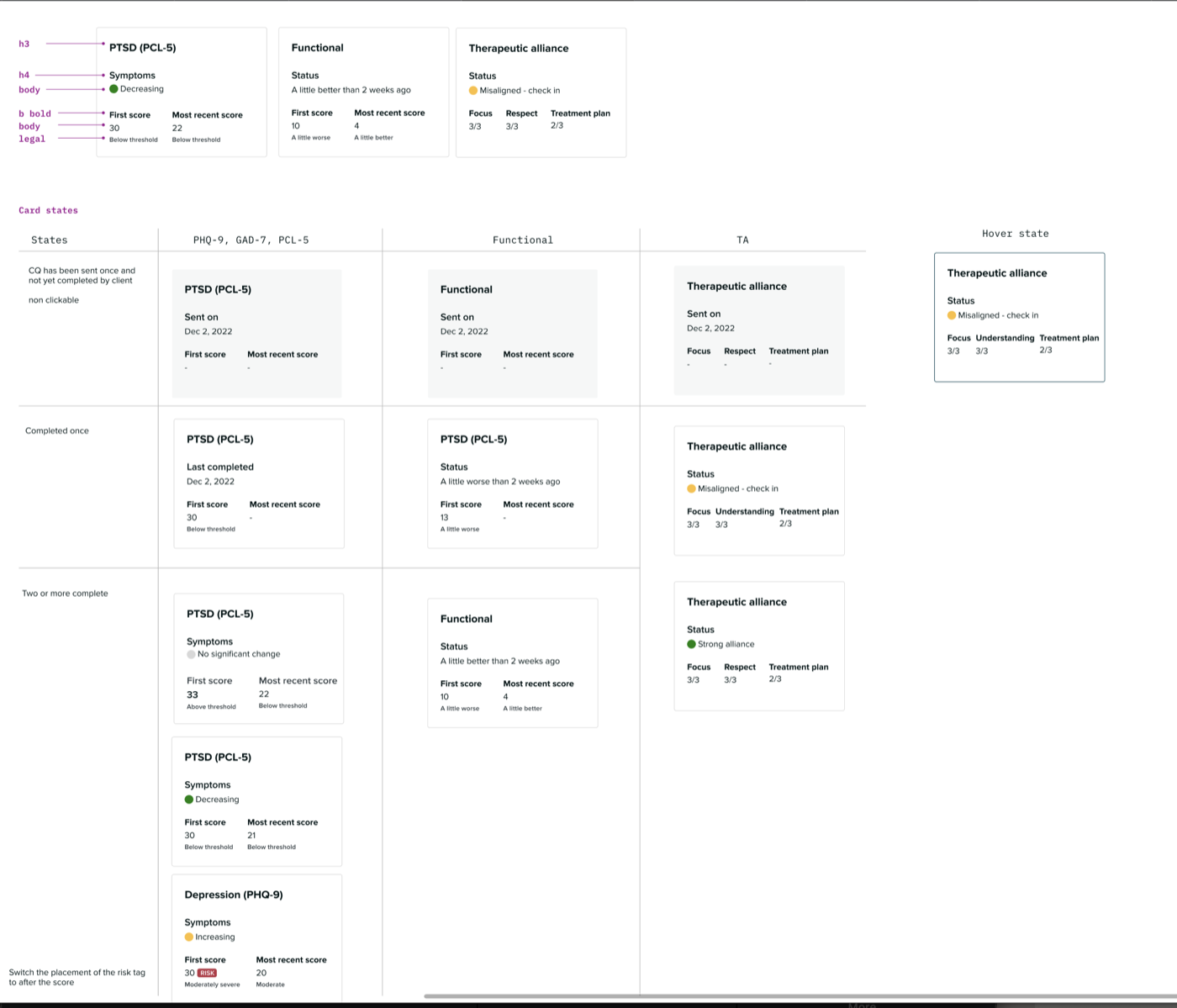
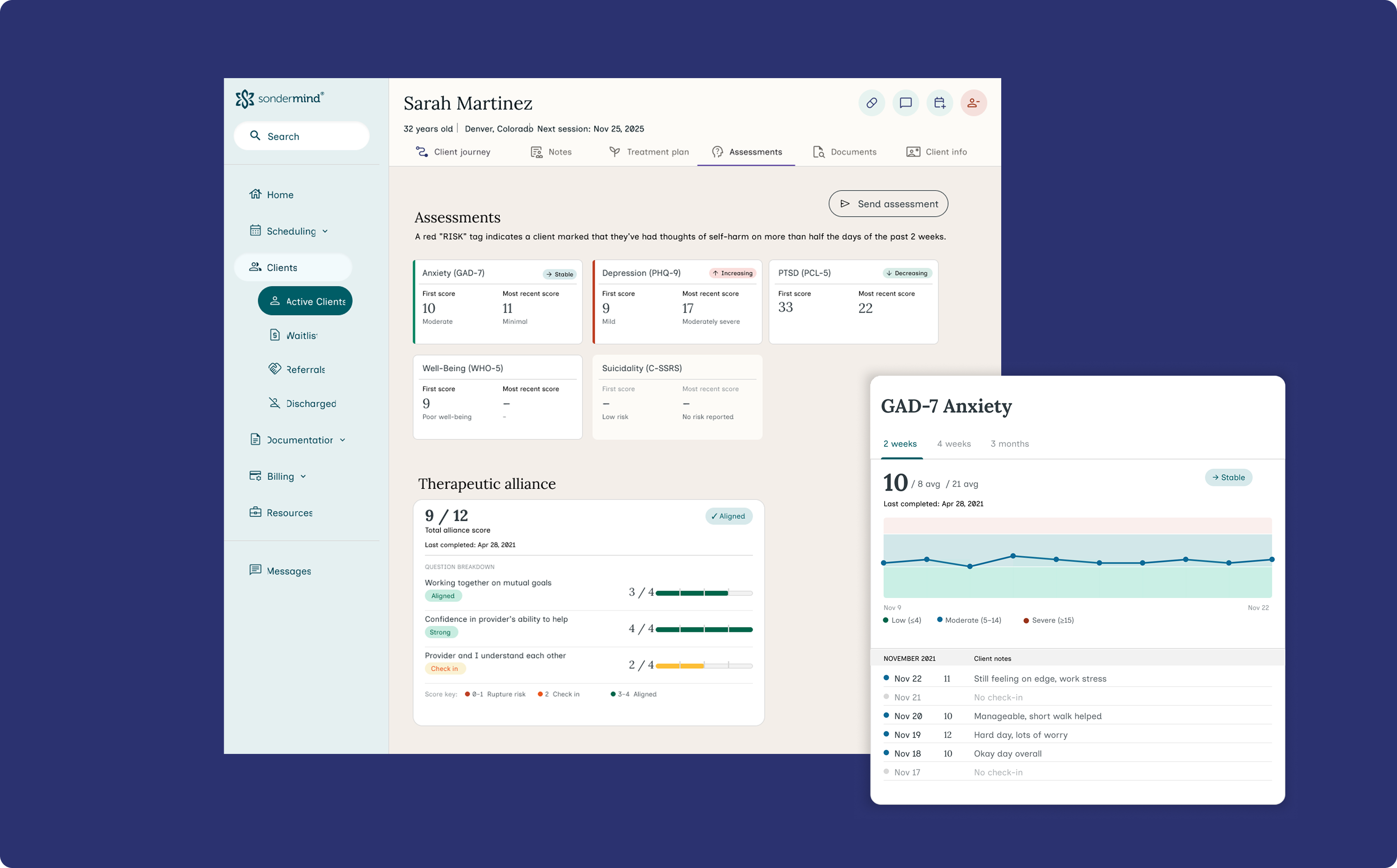
- Every participant expected some kind of visual showing progress over time. Most wanted individual questions broken out, not just a single aggregate score
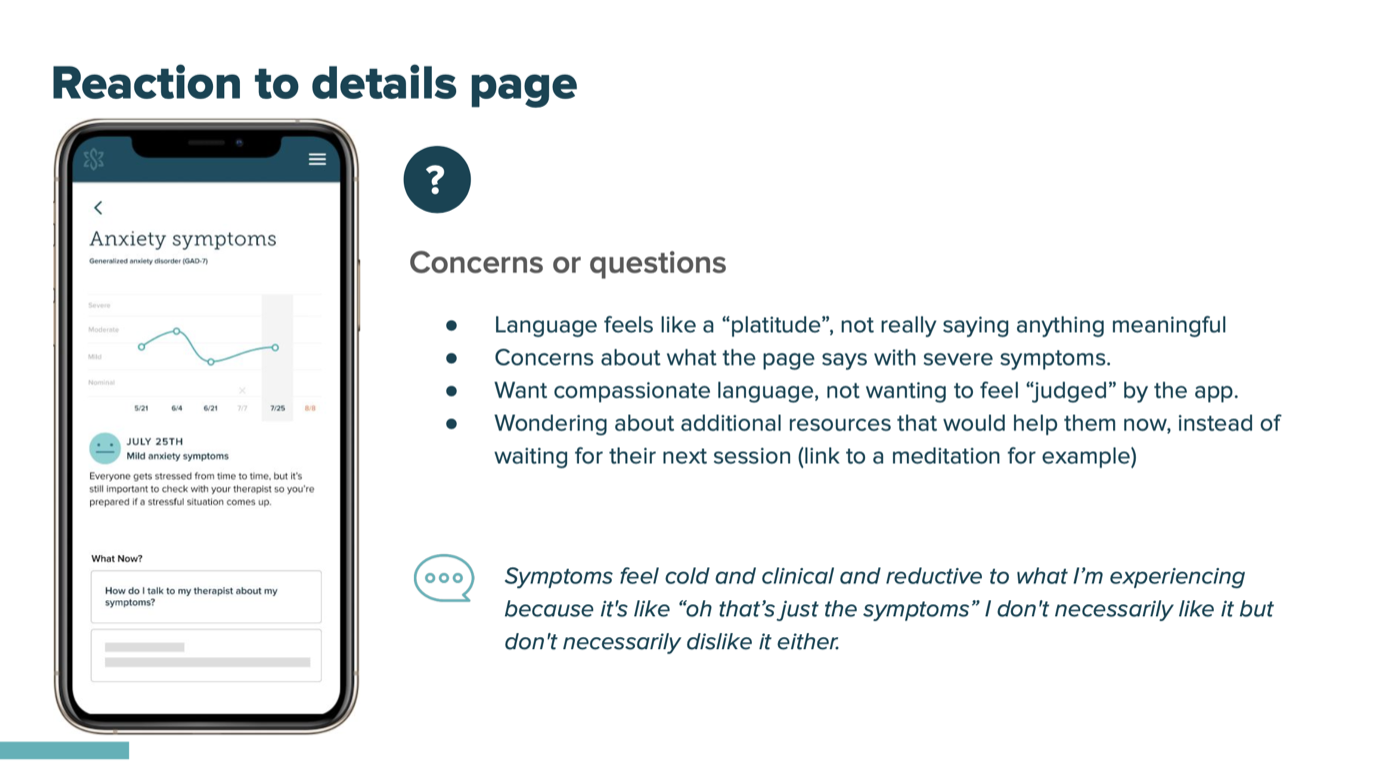
- When symptoms were worsening, participants wanted gentleness and reassurance, not clinical neutrality
- Strong expectation that their therapist was reviewing the data and would bring it up in session
Round 2 — Moderated usability testing with SonderMind clients · 5 participants
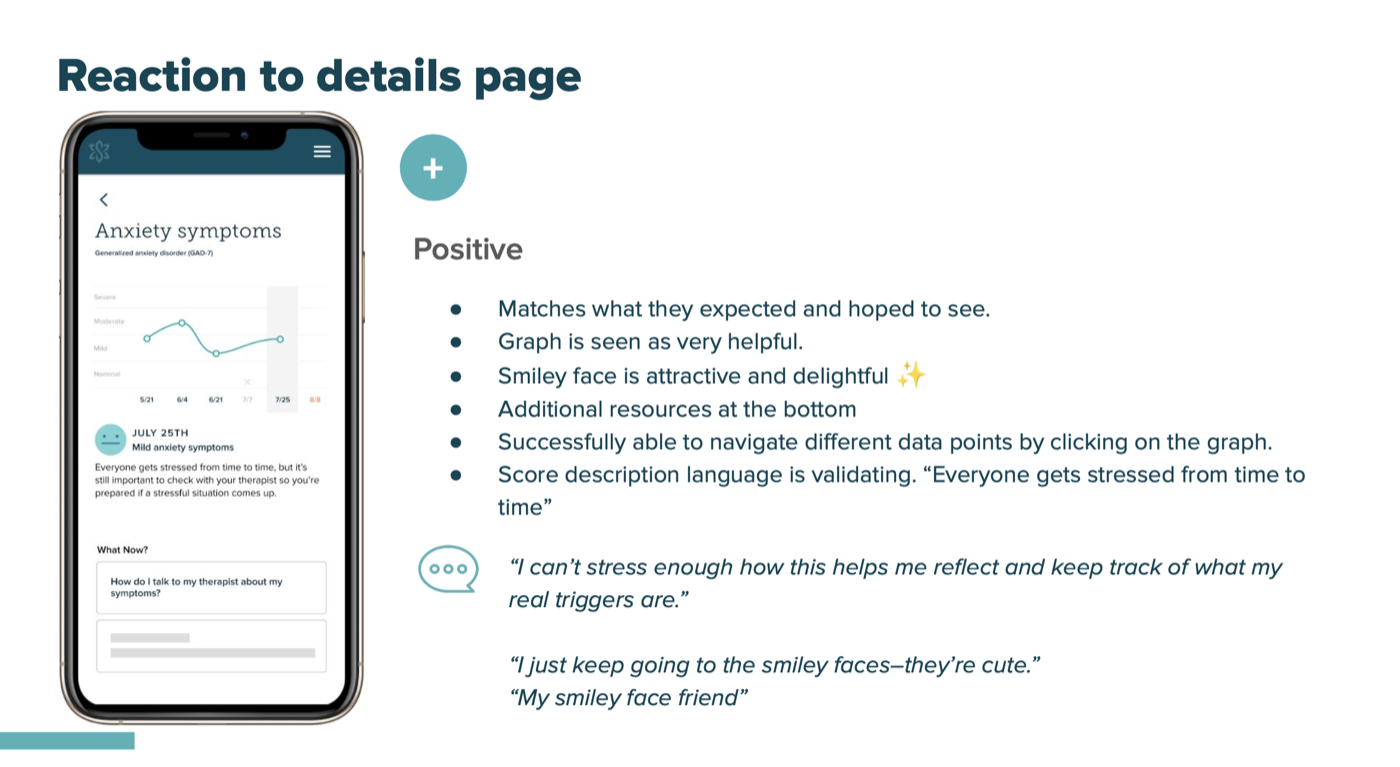
The design landed. The language still needed work.
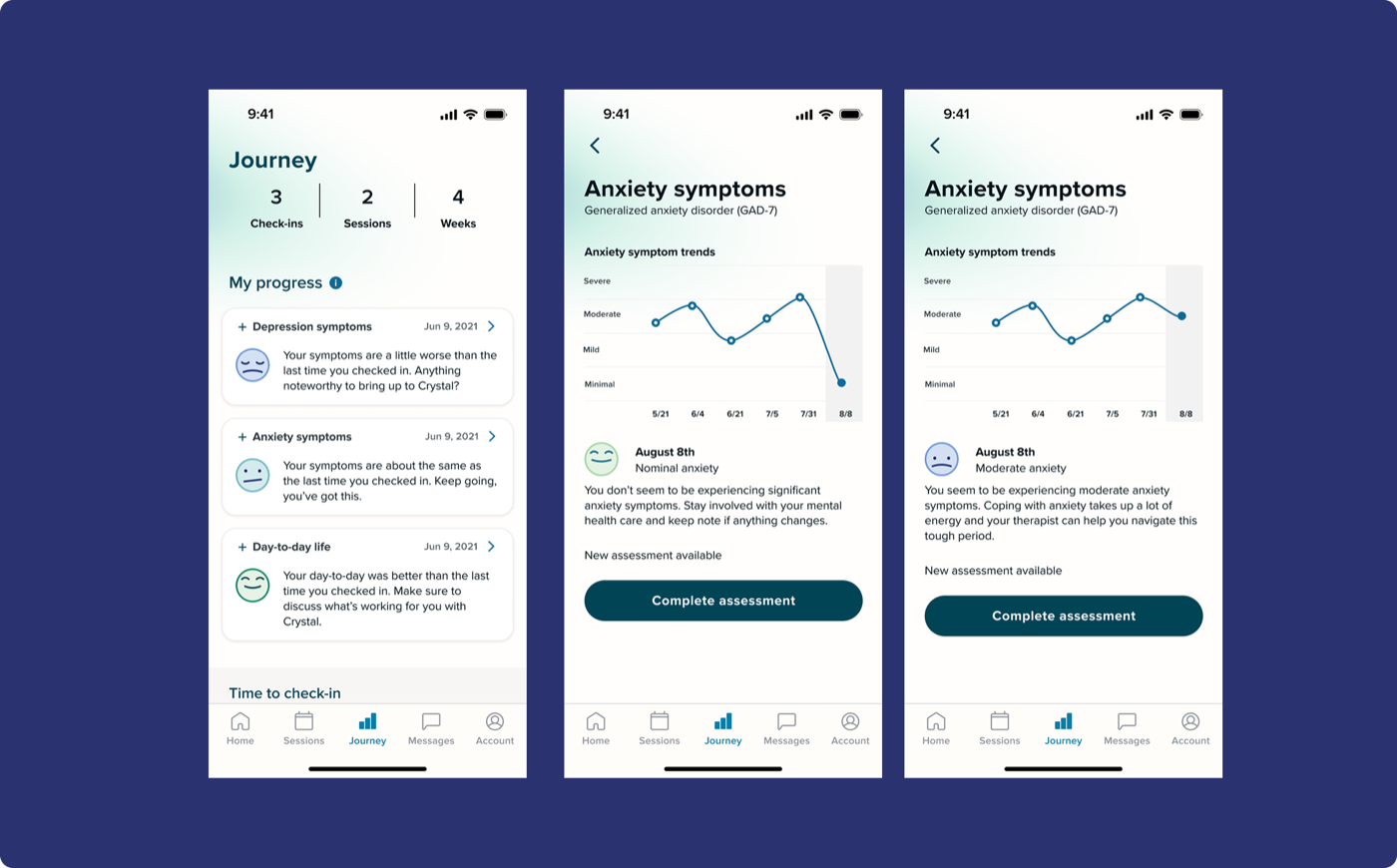
- "Therapy journey" as a name resonated immediately: "Therapy is a journey right? It's about getting better, even if the numbers get worse."
- The graph was well-received. The smiley face was described as "delightful" and "my smiley face friend"
- Language around severe symptoms still felt too clinical, validating but not meaningful. "Symptoms feel cold and clinical and reductive to what I'm experiencing."
- Participants wanted resources for right now, not just at their next session